使用朴素贝叶斯进行分类
分类阶段比较简单,直接应用贝叶斯公式就可以了,让我们试试吧!

通过训练,我们得到以下概率结果:
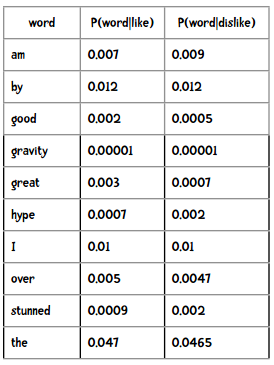
比如下面这句话,要如何判断它是正面还是负面的呢?
I am stunned by the hype over gravity.
我们需要计算的是下面两个概率,并选取较高的结果:
P(like)×P(I|like)×P(am|like)×P(stunned|like)×...
P(dislike)×P(I|dislike)×P(am|dislike)×P(stunned|dislike)×...
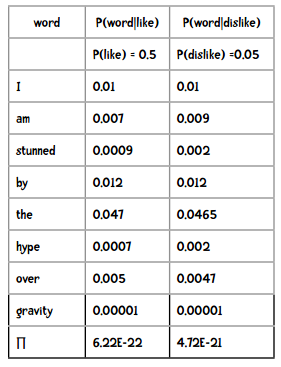
因此分类的结果是“讨厌”。
提示 结果中的6.22E-22是科学计数法,等价于6.22×10-22。

哇,这个概率也太小了吧!
是的,如果文本中有100个单词,那乘出来的概率就会更小。
但是Python不能处理那么小的小数,最后都会变成零的。
没错,因此我们要用对数来算——将每个概率的对数相加!
假设一个包含100字的文本中,每个单词的概率是0.0001,那么计算结果是:
>>> 0.0001 ** 100
0.0
如果我们用对数相加来运算的话:
>>> import math
>>> p = 0
>>> for i in range(100):
... p += math.log(0.0001)
...
>>> p
-921.034037197617
提示
- bn = x 可以转换为 logbx = n
- log10(ab) = log10(a) + log10(b)